Overview
🤔 Why does user’s request for a generic “videogame plumber” lead image-generation models such as Playground v2.5 and DALL·E 3 to produce Nintendo’s Mario? Does user’s “gotham superhero” request necessarily mean they want an image of DC Comics’ Batman?
Despite implemented guardrails, models can still be triggered by names, keywords, or descriptions to generate copyrighted characters. This mismatch between generic prompt and specific output with potential copyright risks raises serious legal concern. Our project makes the following contributions:
- First, we build CopyCat, an evaluation suite with a diverse set of popular copyrighted characters and a novel evaluation pipeline. We apply the evaluation suite on 5 image-generation models (Playground v2.5, Stable Diffusion XL, PixArt-α, DeepFloyd IF, DALL·E 3), and one video generation model (VideoFusion).
- Second, we demonstrate ways to semi-automatically identify keywords or phrases associated with a character are enough to generate their image, without mentioning their name.
- Third, we find that existing mitigations are not fully effective and suggest new strategies.
- Last but not the least, we summarize some key takeaways for users and model deployers.
CopyCat
Evaluation Suite

We build CopyCat, an evaluation suite with a diverse set of popular copyrighted characters and a novel evaluation pipeline, to better ground our investigation and evaluation.
1. Copyrighted Characters
CopyCat includes a dataset with 50 diverse popular copyrighted characters from 18 studios, both US and international.
2. Similarity evaluator
CopyCat uses a GPT4-based evaluator to detect similarity with copyrighted character in generated images, resulting in a DETECT score.
3. Consistency evaluator
CopyCat also measures whether the generation is consistent with the user's intent (i.e., utility), using a CONS score indicating if the main characteristic (e.g., “cartoon mouse” for Mickey Mouse) is present in the generation.
Indirect Anchors Generate Copyrighted Characters
We formalize two modes of copyrighted character generation: (1) Character Name Anchoring: User prompt contains character name directly, and (2) Indirect Anchoring: User prompt contains keywords or descriptions without the character’s name. Indirect anchoring is especially important for both model deployers and model users: even a non-malicious user could accidentally copyrighted characters when using seemingly innocuous prompts, leading to potential legal liability for the model deployer as well as any unsuspecting user that tries to monetize the image.
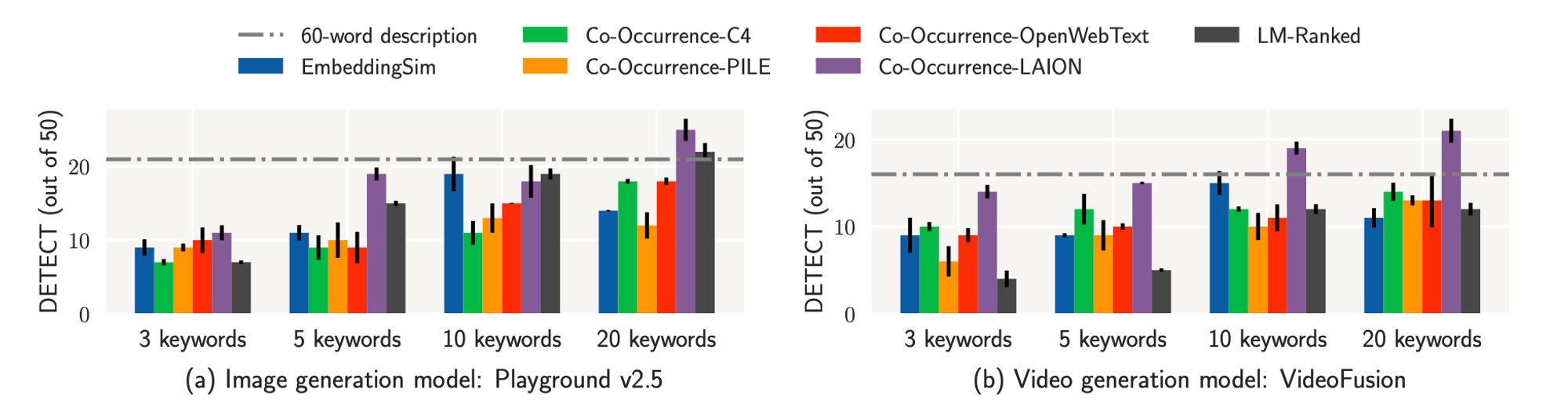
We introduce a generation + reranking pipeline to semi-automatically discover keywords or phrases that can be effective indirect anchors. We first generate a candidate set of keywords, then we use the following 3 reranking approaches to semi-automatically discover indirect anchors:
- LM-Ranked: using greedy decoding to capture the inherent ranking of LMs.
- EmbeddingSim Ranked: rank by their embedding space distance to the copyrighted character’s name.
- Co-Occurence Ranked: rank by their co-occurrence with the character’s name in popular training corpora.
We find that in general, ranking keywords based on their co-occurrence with the character’s name in the LAION corpus is the most effective and could more characters than using a 60-word description when only 20 keywords are used. In addition, we find that descriptions and identified keywords also transfer to generating characters from DALL·E 3 and video models.